Implementing Sequential Testing in an A/B/n Testing Program
To Peek or Not to Peek
In experimentation, peeking at the results prior to obtaining the required sample size violates a cardinal rule of A/B/n testing. Peeking early increases the likelihood of falsely rejecting the null hypothesis as the p-value can oscillate between significant and not significant while more samples are gathered. But waiting is hard. It consumes time and money, and in the case of a bad test feature, can harm the user experience. What if there was a way to monitor data as you collect it—while maintaining statistical integrity?
Here’s where sequential testing enters the mix:
Sequential testing is not a new concept; it was first introduced after WWII (Wald, 1945), and is the process of sequentially monitoring data as it is collected. Hence, peeking is allowed—even encouraged—and you don’t even need to determine the number of permitted “peeks” before the experiment.
Want to Know More?
Typically, one of the first steps taken before an A/B/n test is performing a power analysis to estimate the minimum number of samples required to achieve statistical significance. In sequential testing, this step is no longer necessary since the sample size is data dependent.
You might wonder, why is it acceptable to peek at the data multiple times without increasing the likelihood of a Type-I-Error (e.g., falsely rejecting the null hypothesis)? It’s because two statistical boundaries are created in sequential testing.
These top and bottom boundaries are commonly based on the error rates defined for the test. If the top boundary is crossed, the null hypothesis is rejected, and if the bottom boundary is crossed, the null hypothesis is not rejected. Each time a new data point is observed, the experimenter will take the log-likelihood ratio of the data and compare it to the boundaries.
These borders are not static—instead, as the sample size increases, they narrow, culminating in a triangle shape. This minimizes the danger of erroneously stopping the test early, which would only occur if extreme results were witnessed during the test.
Peeks into the data will fall in one of three buckets:
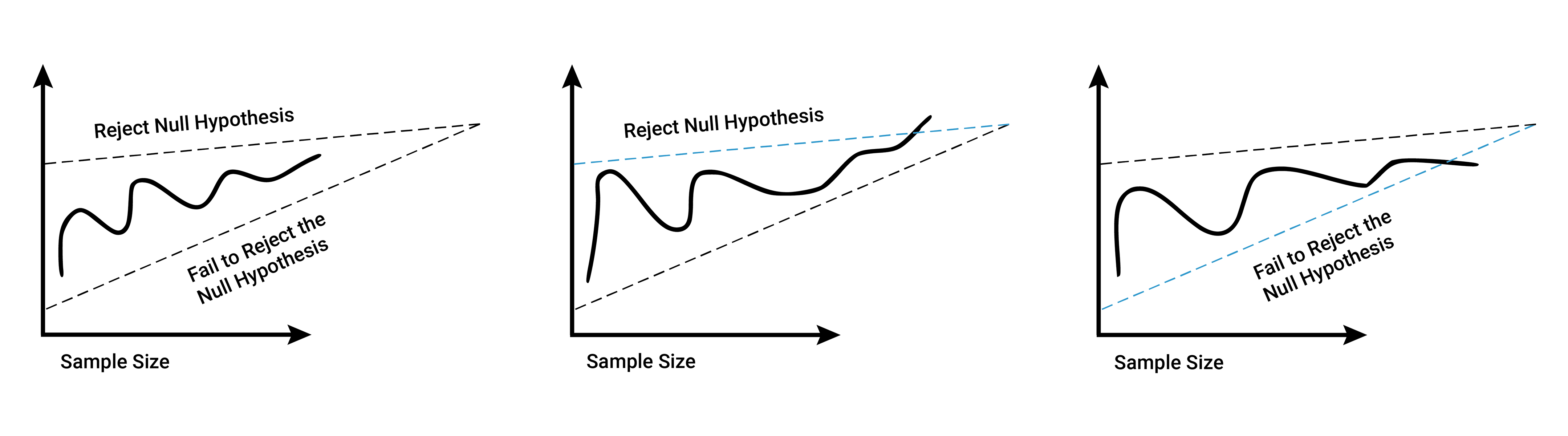
- No boundary crossed: the test continues, for there is not enough evidence to reject or fail to reject the null hypothesis
- Top boundary crossed: the test stops and you reject the null hypothesis
- Bottom boundary crossed: the test stops and you fail to reject the null hypothesis
Is sequential testing right for you?
The greatest upside of using sequential testing is efficiency. It is possible to reduce the sample size by 50 percent and end the test earlier than with other testing methods (Schnuerch & Erdfelder, 2020; Wald, 1945). This is great news when faced with limited resources such as budget, time, and/or traffic volume.
When running a typical A/B/n test, the experimenter is blind to the data and key statistical measures, such as confidence intervals and p-values. However, with sequential testing, team members can stay up-to-date on test performance, which is a game-changer allowing you to roll out features to all customers sooner, or pull back if it detracts from the user experience.
If efficiency is a priority in your experiment, implementing sequential testing could be the right approach.
UPDATE: Google’s Optimize A/B testing platform will sunset in September 2023. If your testing program uses Optimize, we can help you migrate to another tool. We’re experts in all the leading platforms. Contact us about working together to evolve your A/B testing program.
Learn more about our testing and experimentation capabilities.
References
Schnuerch, M., & Erdfelder, E. (2020). Controlling decision errors with minimal costs: The sequential probability ratio t test. Psychological Methods, 25(2), 206–226.
Wald, A. (1945). Sequential Tests of Statistical Hypotheses. The Annals of Mathematical Statistics, 16(2), 117–186.
Written By

Tracy Burns-Yocum
Tracy Burns-Yocum is Analyst I on our Experimentation & Strategy team. She conducts analyses and identifies trends that inform strategic business decisions for clients. She is Google Analytics and Amplitude certified, with additional training in Tableau, SQL, and Python. Tracy also has a background in research to understand human behavior.